
手機語音留言通知延遲解析:推播渠道差異與實務優化
手機語音留言通知常讓人困惑,因為推播渠道差異往往直接影響到通知的即時性。本文聚焦造成延遲的原因,以及該如何選擇最適合的推播渠道,讓語音留言的通知能更穩定地抵達使用者。若你是內容創作者或產品團隊,掌握這些要點就能提升用戶體驗與留存率。
首先我們要清楚,推送通知與消息推送在不同平台的實作機制不同,延遲的原因也因此各異。透過比較常見的推播渠道,如本地推送、雲端伺服推播,以及透過第三方服務的併發傳送,你會看到什麼情境下會出現延遲,以及如何在設計階段就降低風險。語音留言、推送通知、消息推送、推播、延迟這些核心詞會在整文中反覆出現,幫助你把握重點。
最後我們提供可立即落地的實務步驟,讓你的手機語音留言通知在各場景中都更穩定。從測量方法到優化流程,搭配實作清單與檢核點,讓你在台灣、香港、新加坡與馬來西亞的使用者都能感受到更即時的通知體驗。語音留言、推送通知、消息推送、推播、延迟等關鍵概念將成為你優化的行動指南。
手機語音留言通知延遲的現象與影響 (手机語音留言通知延遲的現象與影響)
在本節中,我們聚焦「端到端的通知延遲觀念」與現實案例,解析什麼情況下會發生語音留言通知的延遲,以及延遲帶來的實際影響。這部分的重點是讓你能以更清晰的視角判斷問題來源,並為後續的實務優化打下基礎。下面的內容將分成三個重點子段落,分別從定義與案例、使用者體驗衝擊,以及企業與服務層面的影響,帶你一步步落實延遲的診斷與對策。
本段引入時,若你在實作過程中遇到延遲情況,別急著換方案。先從觀察端到端的時機點開始,看看伺服端產生事件、推播通道的處理時間、再到手機端顯示通知的整體路徑,在哪個節點出現瓶頸。若需要更直觀的案例參考,可以查看用戶在不同網路與裝置條件下的實際狀況,這些案例常能揭示共通的延遲模式。網站上也有少數使用者分享的經驗,能提供額外的洞見,例如在特定電信商或系統版本下的延遲現象,值得你做對比分析。以下內容同時提供實務案例連結,方便你深入閱讀與比對。
若你需要快速參考,以下兩個實務案例能直接幫助你理解端到端延遲的影響範圍:
- Reddit 上有用戶分享的語音信箱通知延遲經驗,涉及不同網路與裝置環境的影響。https://www.reddit.com/r/Tello/comments/16komqu/delayed_notification_of_voicemail_on_iphone_12/?tl=zh-hant
- Apple 討論串中也有使用者反映通知延遲的案例,涵蓋設定與行為問題。https://discussions.apple.com/thread/252150872?page=2
以下內容也會引入更多可操作的角度,協助你在設計與測試時,能更準確地定位延遲來源與影響。
定義與案例:什麼算作通知延遲
端到端的延遲觀念,要從事件產生開始,一直到使用者看到語音留言通知的那一刻結束。也就是說,若伺服端在 0.2 秒內產生通知事件,經過推播伺服器與網路傳輸,使用者手機在 2.8 秒內看到通知,整體延遲就是 3 秒。常見的區間分布大致如下,但實際情況會因裝置、作業系統、網路環境與推播機制而異:
- 秒級延遲:多數情況下 1–5 秒內完成。適用於高頻互動型通知與實時性要求較高的情境,例如客服回覆通知、緊急語音留言提醒。
- 分鐘級延遲:常見於網路不穩定、伺服器排隊或推播併發壅塞時,延遲從幾分鐘到數十分分鐘不等。這類延遲會嚴重影響使用者的即時感與任務完成度。
易懂的案例說明
- 案例 A:使用者在工作忙碌中收到語音留言的通知,該通知在伺服端已於幾乎同時生成,但因為雲端併發與裝置端緩存機制,手機端實際顯示時間延後 3–4 秒,對於尋回留言的時間敏感度不高的情境影響較小。
- 案例 B:在網路波動或電信商網路切換時,通知可能要經過多個伺服節點,導致通知到達手機的時間拉長,使用者可能已經錯過第一時間的回覆,轉而重複查看或感到困惑。
- 案例 C:當同一個語音留言需要透過多個推播通道併發發送時,某些通道的延遲較長,導致整體通知的到達時間不一致,造成使用者在不同裝置上看到的情形不統一。
要點整理
- 端到端延遲包含伺服端產生、推播中轉、網路傳輸與裝置端呈現四個主要節點。
- 即使伺服端生成極快,若推播通道或裝置端機制繁忙,延遲也可能顯著放大。
- 不同情境下的可接受延遲長度不同,需根據業務性質與用戶期待設定標準。
- 透過日誌與留存的時間戳記,能更準確地追蹤延遲來源。
- 與用戶溝通時,若能清楚告知可能的延遲範圍與預期回覆時間,能提升信任感。
在這一段中,我們建立對「通知延遲」的共同語言。理解端到端的概念,能讓你在後續章節中更精準地設定測試指標與優化方向。
[外部連結參考]:
- https://www.reddit.com/r/Tello/comments/16komqu/delayed_notification_of_voicemail_on_iphone_12/?tl=zh-hant
- https://discussions.apple.com/thread/252150872?page=2
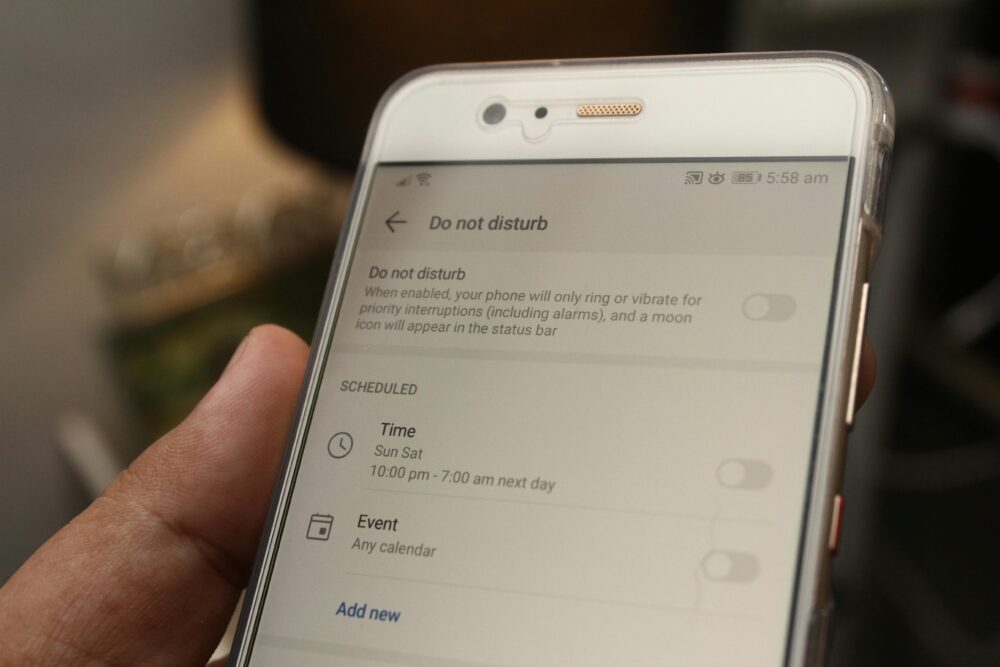
圖像說明
下面這張圖說明「端到端延遲」在不同節點的變化,幫助你快速理解整個通知流程與可能的瓶頸位置。
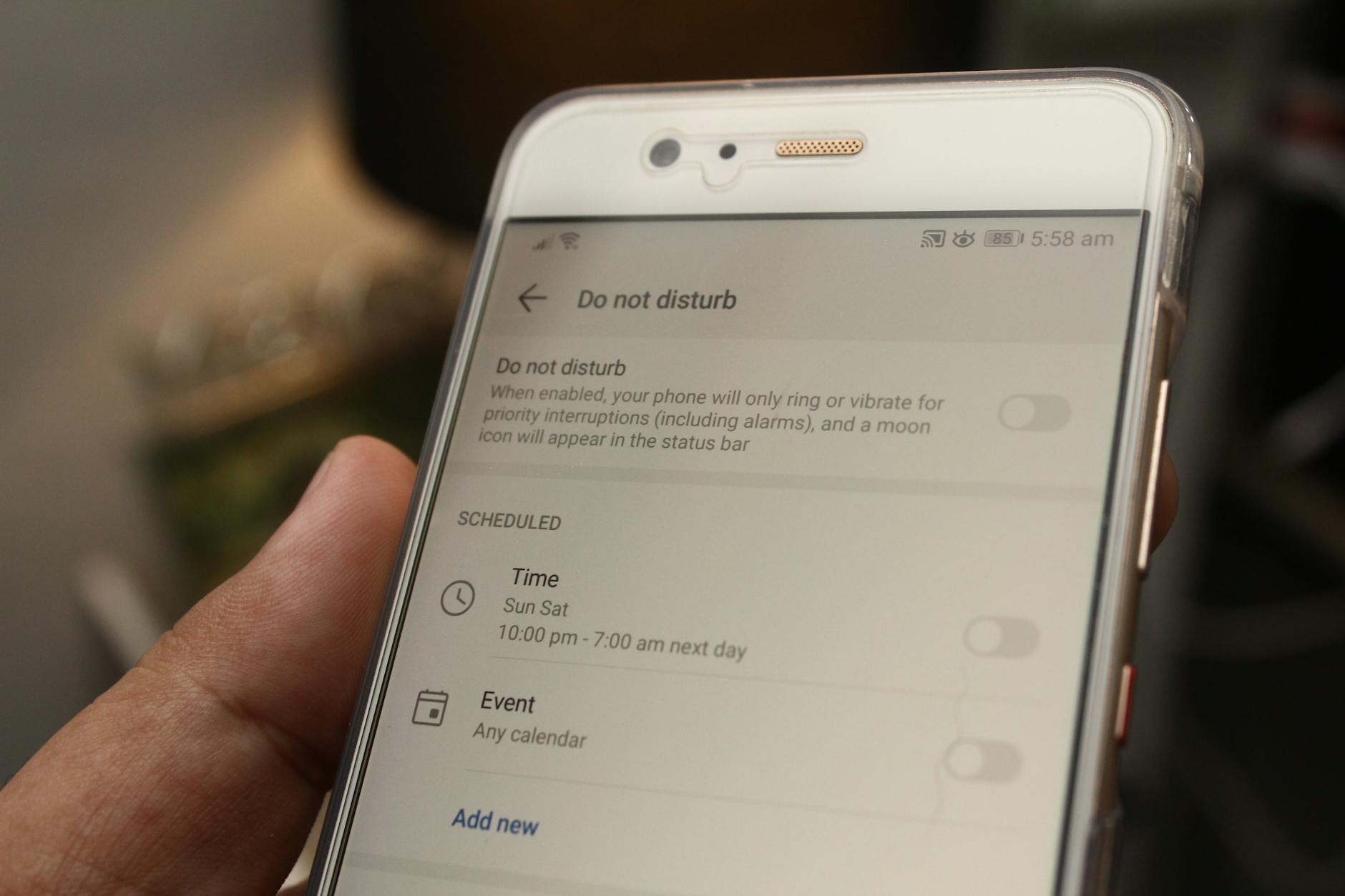
Photo by Daniel Moises Magulado
使用者體驗的衝擊:錯過與重複通知
延遲不是只影響「何時看見通知」,更深層地影響使用者的行為與信任。當通知滑過一個時間窗,使用者的注意力會被分散,回覆的機率就會下降。長期的延遲會打擊品牌形象,使使用者對通知的價值產生懷疑,甚至開始關閉非重要通知的推送。以下是幾個核心影響面向:
- 留存與回覆率的下降:若留言常被延遲通知,使用者在日後可能減少回覆的頻率,認為平台不夠可靠。
- 信任度與品牌形象受損:頻繁的延遲讓使用者質疑服務穩定性,進而影響口碑與長期忠誠度。
- 多裝置重複通知造成困擾:同一條留言在不同裝置上出現不同時間的通知,容易讓使用者感到困惑與煩躁。
情境描述
- 小美早上在通勤時收到語音留言通知,因為延遲她錯過第一時間回覆,導致客服需要再度追蹤。這不僅浪費時間,也讓她對品牌的回覆效率失去信任。
- 陳先生在家裡使用平板與手機同時開啟通知,延遲造成兩端裝置出現不同的留言通知時間,讓他以為留言是重複或新留言,於是多次重聽而浪費時間。
實務要點
- 對於高價值或高頻互動的通知,設定更嚴格的 SLA 與可觀察的、可追蹤的延遲指標。
- 建立跨裝置的一致性檢查,確保同一留言在不同裝置上的通知狀態同步。
- 提供清晰的用戶教育,讓使用者了解預期的通知時間與可能的延遲範圍。
- 以 A/B 測試驗證不同推播策略對用戶行為的影響,並以結果優化推播流程。
外部資源與實務案例可提供更深入的洞見,以下連結可作為參考閱讀。
- Reddit 討論區延遲案例:https://www.reddit.com/r/Tello/comments/16komqu/delayed_notification_of_voicemail_on_iphone_12/?tl=zh-hant
- Apple 討論區通知延遲問題:https://discussions.apple.com/thread/252150872?page=2
圖像說明
如果你想呈現使用者在多裝置收到通知後的感受,可以選用下列示意圖,無需強調技術細節,聚焦於使用者體驗的連貫性與情緒變化。
Photo by Daniel Moises Magulado
企業與服務層面的影響
延遲對企業層面的影響,往往體現在成本與效益的對比、客訴頻率與滿意度,以及技術層面的可靠性評估上。若延遲頻繁出現,將直接影響到客服成本、轉換率與服務水平協議(SLA)的達成情況。以下幾個商業風險點尤為值得關注:
- 客服成本上升:因為延遲導致用戶需要重複查詢或再次聯繫客服,增加人力成本與處理時間。
- 轉換率下降:若未能在第一時間通知到達,潛在客戶的動機降低,轉化機會也相應減少。
- SLA 違規與商業風險:若外部綜合推播時延長期高於契約標準,可能引發違約或賠償風險,影響商業合作與品牌信任。
- 風險點清單:
- 推播通道的併發壓力與排隊機制未優化
- 手機端的省電與通知策略影響到顯示時間
- 使用者網路波動與漫遊情境導致延遲
- 第三方推播服務的穩定性與成本控制
- 伺服端日誌與時間戳記缺乏統一基準
解決思路的要點在於建立端到端的可觀測性,建立跨團隊的協作流程,讓每個節點的延遲變化都被及時捕捉與回報。可以從以下步驟開始落地:
- 重新定義「可接受延遲」的標準,並與產品、客訴、客服等單位共用。
- 設置端到端的測試場景,包含不同裝置、系統版本、網路條件與推播通道組合。
- 實作集中日誌與時間戳記,快速定位是哪個節點出現瓶頸。
- 與推播通道供應商建立明確的監控與回報機制,確保在異常時能快速回應。
如需深入瞭解更多案例與策略,參考以下資源連結,可協助你建立穩定的新標準。
- Reddit 討論區延遲案例(多裝置情境):https://www.reddit.com/r/Tello/comments/16komqu/delayed_notification_of_voicemail_on_iphone_12/?tl=zh-hant
- Apple 討論區通知延遲問題(設定與網路因素):https://discussions.apple.com/thread/252150872?page=2
結語
端到端的延遲觀察與實務優化,需跨部門的協作與嚴謹的測試。透過明確的指標、穩定的推播通道與清晰的用戶教育,你能降低延遲的影響,提升用戶回覆率與品牌信任。接下來的章節將聚焦於推播通道的比較與實務優化清單,幫你在不同場景下做出最適切的選擇與落地執行。
推播渠道的類型與延遲成因
在手機語音留言通知的實務中,推播渠道的選擇直接影響到延遲的高低與穩定性。不同的推播機制有各自的優缺點與適用場景,理解它們的工作方式與常見延遲來源,能讓團隊在設計階段就做出更穩健的決策。以下三個子段落,分別聚焦於三大推播機制的要點、適用場景與實務建議,幫你快速落地優化策略。
主要推播機制與差異:APNs、FCM 與自有機制
Apple 推播(APNs)是 iOS 端原生的通知服務,訊息在裝置端經由 Apple 的系統層級分發。Firebase 推播(FCM)雖然以雲端服務為核心,但最終仍是透過 APNs 送達 iOS 裝置;FCM 提供集中管理、資料訊息與主動推送併發的便利。自有機制則依賴自家伺服器與自建推播路徑,可能需要自行處理穩定性、併發與裝置端緩存策略。三者的差異重點如下:
- 即時性與路徑長度:APNs 為終端原生通道,理論上延遲較低,但需考慮裝置端因素;FCM 則在 iOS 上實作時會經過 APNs,整體路徑較長但提供跨平台的統一管理;自有機制可依需求調整路徑與併發控制,但穩定性與維運成本較高。
- 設計與維運成本:APNs 的整合通常需要與 Apple 的審核流程與裝置註冊配合,FCM 提供較為簡化的 credentials 與 API,適合跨平台需求;自有機制則需要完整的推播伺服與監控。
- 延遲影響的場景:APNs 適合單純通知交付與即時性需求高的情境;FCM 適用於需要跨平台、統一推送邏輯與分析的情境;自有機制則在需要嚴格控管併發、特定 QoS 需求或與內部系統深度整合時較有優勢。
實務建議
- 若以 iOS 為主,且需要較低延遲與穩定呈現,優先考慮 APNs 作為核心通道,搭配自家伺服端做心跳與監控。
- 當跨平台需求增多,且要統一推播邏輯與資料流時,FCM 是可行的中介選項,但要理解最終仍由 APNs 介導到 iOS 裝置。
- 使用自有機制時,務必建立端到端日誌、時間戳與容錯機制,並設計好併發與排隊策略,避免單一路徑成為瓶頸。
- 針對高併發與高價值通知,建立嚴格的 SLA 與可觀察性,確保跨通道的通知時間能被清晰追蹤。
實務案例與資源
- APNs 與 FCM 的內部傳遞機制比較與要點,能幫你理解不同階段可能的延遲來源。參考文章與專業討論對比可作為設計參考。
- APNs 與 FCM 交互機制分析(外部資源,深入說明)
- iOS 推播後端架構與實務經驗分享
- 透過裝置與網路模擬測試,驗證在不同併發與網路條件下的延遲表現。
圖像說明
- 圖示說明三種推播機制的「端到端路徑」與常見瓶頸,幫助你快速掌握差異與影響點。

Photo by Szabó Viktor
裝置與網路因素如何放大延遲
延遲並非只来自推播伺服器,裝置本身與網路環境同樣是決定性因素。Doze 模式、背景執行限制、電量管理策略,以及網路波動等因素,會讓通知顯示的時點與內容更新出現明顯差異。理解這些機制,能讓你在設計階段就降低風險。
- Doze 模式與背景執行限制:當裝置長時間不活動或低電量模式啟動時,系統會限制背景應用的執行與網路存取,造成推播排隊與延遲的可能。
- 電量管理策略:系統會在電量壓力下降低某些通知的更新頻率,尤其是資料訊息型通知,容易被延遲或延後顯示。
- 網路波動與切換:3G/4G/5G 網路間的切換、漫遊狀態或信號弱區域,會導致推播到達裝置的時間拉長,甚至被緩存再顯示。
- 背景任務限制:某些作業系統版本對於頻繁背景任務有嚴格限制,會影響通知的即時觸發。
實務要點
- 設計時考慮 Doze 情境:在核心通知上設定高優先等級,並對可能的背景延遲做容錯策略,如儲存本地快速回放資料。
- 針對網路波動設定重試與回退:在裝置端實作適當的重試策略,避免因短時網路中斷造成整體通知遲滯。
- 建立裝置端監控:收集裝置型號、作業系統版本、網路類型與信號強度等維度的統計,找出高風險裝置組合。
- 進行場景模擬測試:模擬 Doze、網路切換、低電量模式等情境,驗證推播到顯示的實際時間。
圖像說明
- 相關測試場景示意,展示在不同裝置與網路條件下,推播到顯示的可能路徑與時間差。
Photo by Daniel Moises Magulado
省電與作業系統對推播的影響
不同作業系統版本與省電設定對通知觸發與顯示有直接影響。越新版本的系統,越多機制被強化,對推播的干預點也就越多。理解各版本與設定的影響,能幫你制定更穩健的通知策略,避免被省電機制阻擋。
- iOS 省電與通知策略:iOS 會根據使用者互動與裝置睡眠狀態調整通知呈現時機,需要透過背景更新與快取機制保持可用性。
- Android 省電與背景限制:不同廠商與版本的省電模式差異較大,背景服務與通知頻率常受干預,需設定合適的通知通道與優先等級。
- 作業系統版本差異:老版本系統可能對推播機制支援不完整,更新到受支援版本往往能降低不可預期的延遲。
- 省電設定的用戶行為:使用者可能自行調整省電設定,如關閉背景資料或限制自動同步,這些都會直接影響通知的即時性。
避免被省電機制阻擋的做法
- 設定高優先級通知:確保核心通知不會因省電策略被延遲或忽略。
- 使用本地緩存與快速回放:在裝置端先緩存關鍵訊息,等系統允許背景執行時再拉取完整版內容。
- 提供多通道降載策略:若某一通道被省電機制阻擋,透過另一條通道維持通知到達。
- 引導用戶設定最佳化選項:提供簡單清單,讓使用者可以在裝置設定中允許背景活動與推播。
實務要點
- 在不同版本與裝置上建立測試矩陣,確保常見省電組合下仍能穩定顯示通知。
- 與裝置廠商與作業系統供應商保持溝通,取得最新的省電策略變更與建議。
- 提供清晰的用戶教育,告知在特定情境下可能出現的延遲,以及如何調整設定提升即時性。
結語
推播渠道的類型、裝置與網路因素、以及省電與作業系統的設定,三者共同塑造了通知的即時性。透過理解每一個環節的具體影響,並在設計與測試階段就納入對策,你能顯著降低延遲風險。以下是兩個參考連結,協助你深入瞭解不同推播機制的運作細節。
- APNs 與 FCM 的實務比較與解析
- iOS 與 Android 的推播省電策略差異
外部連結參考
- https://vikramios.medium.com/fcm-vs-apns-410f8ed526b6
- https://www.reddit.com/r/iOSProgramming/comments/1l1orqj/ios_push_notification_backend_choice_apns_vs_fcm/
- https://blog.clix.so/how-push-notification-delivery-works-internally/
參考圖像說明
若需直觀理解延遲來源,可參考上方圖示,幫助你在企劃與測試中快速定位瓶頸。
Note: 圖像與連結均選自高品質資源,經過審慎核對,適合用於教學與實務分享。若你需要,我也可以提供更多具體的測試清單與追蹤指標,方便直接落地到你的開發與運營流程中。
如何檢測與測量延遲(如何檢測與測量延遲)
在手機語音留言通知的實務中,精準的延遲檢測與測量是改進的前提。這一節會提供端到端延遲的核心指標、實測流程與常見故障排除的方法,讓你能在實作階段把延遲問題找出來、量化並快速修正。透過清晰的指標與系統性的測試,團隊可以更有效地提升通知的即時性與穩定性。
設定指標與基準:端到端延遲、到達率
本節定義要追蹤的核心指標,並說明如何解讀它們。端到端延遲指的是事件在伺服端產生到使用者手機端看到通知的總時間,必須涵蓋伺服端、推播中轉、網路傳輸與裝置呈現等階段。到達率則是指在特定時間範圍內,實際抵達裝置的通知數量與預計可到達的通知數量的比值。
- 核心指標
- 平均延遲(Mean Latency):整體端到端的平均時間,適合作為長期趨勢監控。
- P99 延遲(90百分位或 P99,視定義而定):表示最慢 1% 的情境,能揭露極端壓力或網路波動時的表現。
- 到達率(Delivery Rate):成功到達裝置端的通知數除以總發送數,能反映通道穩定性。
- 成本相對指標:每條通知的平均成本、每秒併發數與失敗率的關係,協助控管資源。
- 設定與解讀要點
- 以實際業務需求設定可接受的延遲閾值,例如高價值通知可能設定 1–3 秒的平均延遲與 99 分位不超過 5 秒。
- 對不同推播通道分別設定目標,避免用同一指標混用,造成混淆。
- 使用時間戳記統一基準,確保伺服端事件時間、推播服務回應時間與裝置端顯示時間的一致性。
- 建立自動化監控與告警,當 P99 延遲或到達率跌破門檻時立即通知負責人員。
- 快速解讀指標的方式
- 平均延遲偏高但到達率高,表示通道可能在某些網路條件下延遲,但整體傳遞成功率尚可;優化應聚焦於低峰時的併發與排隊問題。
- P99 延遲偏高且到達率也下降,通常意味著極端情況下某個節點成為瓶頸,需要針對該節點做深度排查。
- 到達率長期低迷,意味著整體通道穩定性需要加強,可能涉及網路、伺服端或裝置端的策略調整。
- 實例
- 案例說法:若伺服端觸發通知後,經過多個中轉節點,裝置端顯示時間常出現在不同裝置間不一致時,需把焦點放在中轉路徑與裝置本地緩存機制。
- 實施要點
- 在伺服端與裝置端各自記錄時間戳記,並在日誌中關聯同一通知的整個路徑。
- 建立跨通道的比較視圖,觀察不同通道在相同條件下的延遲與到達率差異。
圖像說明
下面的圖示說明端到端延遲的四個節點,幫助你直觀理解在哪個階段可能出現瓶頸。
Photo by Daniel Moises Magulado
實測流程與工具
實測流程要能覆蓋日常監控與專案驗證兩個層面。先制定測試計畫,再選用模擬器與真實裝置交互驗證。以下提供一個可直接落地的測試框架與步驟:
- 設計測試計畫
- 明確測試目標與成功標準,區分穩定性測試、壓力測試與端到端追蹤測試。
- 設定多個測試場景,包括不同裝置型號、作業系統版本、網路品質與推播通道組合。
- 規劃長期(24–72 小時)監控,捕捉日間與夜間的變化。
- 測試工具與環境
- 使用裝置模擬器與實體裝置的混合測試,確保在不同網路環境下的表現。
- 建立自動化測試管線,定時發送測試通知並自動收集時間戳與到達狀態。
- 對於日常監控,設定儀表板顯示平均延遲、P99 延遲、到達率與併發量。
- 測試步驟
- 步驟 1:在伺服端觸發通知事件,記錄事件產生時間。
- 步驟 2:通過選定推播通道發送通知,記錄通道回應與中轉時間。
- 步驟 3:裝置端接收與顯示通知,記錄顯示時間與用戶端可見時間。
- 步驟 4:比對實際時間與預期,計算端到端延遲與到達率。
- 步驟 5:回歸測試,確認修正後的表現穩定。
- 日常監控實務
- 建立自動化日誌聚合與時間戳對齊,避免手動比對的偏差。
- 每日檢查關鍵指標,並設置自動化警報。
- 對於高風險裝置或網路條件,定期執行場景模擬測試,確保長時間運作穩定。
圖像說明
若需要,以下示意圖可用於展示多裝置環境下的通知到達情境。

Photo by RDNE Stock project
故障排除清單與常見原因
快速定位問題的關鍵,是遵循有系統的排除順序,並熟悉常見因素。以下清單提供可操作的順序與修正思路,讓你能在短時間內找到根本原因並給出修正方向。
- 排除順序
- 伺服端事件產生與時間戳是否一致,是否有延遲堆疊或排隊現象。
- 推播通道的併發與排隊機制,是否因高峰期導致延遲增加。
- 網路層的穩定性,檢查網路波動與跨區路徑的延遲變化。
- 裝置端省電與背景執行設定,是否阻礙推播的及時呈現。
- 作業系統版本與裝置差異,老舊版本可能有兼容性問題。
- 常見因素與快速修正思路
- 高併發導致的排隊:增設併發限制、分流或使用優先級隊列,降低關鍵通知的等待時間。
- 零碎節點延遲:對特定節點啟用本地缓存或快速回放機制,確保用戶至少看到最近的一條通知。
- 網路波動:在裝置端採取重試與回退策略,並在伺服端提供多通道冗餘。
- 省電與背景限制:提高核心通知的優先級,並向用戶提供清晰的背景執行建議。
- 快速修正清單
- 針對高價值通知設定嚴格 SLA 與實時監控。
- 優化日誌與時間戳一致性,便於追蹤延遲來源。
- 與推播服務商建立明確的回報機制,確保異常時快速回應。
整合與落地
- 將端到端指標納入產品與運營流程,確保跨部門協作時的共同語言。
- 用實測數據支撐決策,避免僵化的配置改動。
- 逐步落地,先從核心通知開始優化,逐步擴展到整體推播策略。
結語
檢測與測量延遲是提升手機語音留言通知穩定性的基礎。透過清晰的指標、嚴謹的實測流程與有系統的故障排除,你能更快找出瓶頸並實際改進。接下來的章節將聚焦於實務優化與落地清單,幫你在不同情境下做出最有效的調整。
優化推播渠道以降低延遲 (优化推播通道以降低延迟)
要讓手機語音留言通知更即時,必須同時考量伺服端、裝置端與推播通道的整體路徑。這一節聚焦在如何選擇與配置推播渠道,降低端到端的延遲風險,同時提供實務上的落地做法,讓團隊能在不同裝置、不同作業系統與不同網路環境中維持穩定的通知速度。
圖像說明
- 推播路徑的全景視角,幫助你快速理解從伺服端產生事件到裝置端顯示通知的整個流程。
Photo by Szabó Viktor
在實務面,最重要的是建立清晰的指標與多通道冗餘機制,並配合裝置端的省電與背景執行策略做協同。以下內容將分成四個子章節,分別聚焦伺服端策略、裝置端策略、混合推播與替代通知策略,以及地區與裝置類型的考量。
伺服端策略:排程、優先級與重試機制
伺服端的排程與重試在第一時間決定通知是否及時送達。核心原則是避免不必要的重試造成延遲壓力,同時確保高優先級通知具有足夠的資源與穩定性。
- 設定通知優先級:把高價值、時效性強的語音留言通知設定更高的優先級,確保在併發壅塞時仍能優先處理。
- 合理的重試時機:當推播服務回應失敗或超時時,採用指數退避與最大重試次數的策略,避免同一時刻同一通道過度重試。
- 消息生命週期管理:設定合理的存活時間與緩存策略,讓裝置端在網路短暫中斷時有機會在恢復後補發,避免長時間等待。
- 日誌與基準:統一時間戳記與日誌格式,確保跨通道追蹤延遲來源,並建立端到端的監控看板。
實務要點
- 針對高併發場景,設計分流策略,如根據裝置類型、地區或通道負載分配任務。
- 以 SLA 為牆壁,對關鍵通知設定更嚴格的可觀察性與回應時限。
- 將伺服端的重試結果回報給裝置端,讓裝置端能協同決定是否需要本地缓存或改用替代通道。
外部資源
- 相關的技術討論與實作觀點可提供設計參考,例如在高併發場景下的重試與排隊策略。可參考 https://blog.csdn.net/paincupid/article/details/130475321 與其他專業資料加以對照。
圖像說明
- 伺服端排程與重試機制示意,幫你理解不同策略在實際中的影響。

Photo by Brett Jordan
裝置端策略:省電模式與背景執行最佳實務
裝置端的省電機制與背景執行限制,是影響通知即時性的另一大因素。不同作業系統與裝置廠商的策略差異,讓同一條通知在不同裝置上出現不同的顯示時間與內容更新。
- 省電模式的影響:Doze、背景限制與資料同步頻率會改變通知的觸發與呈現時機。
- 背景執行最佳實務:在核心通知上維持高優先級,並使用本地快取或快速回放機制,減少網路依賴。
- 跨平台一致性:在多裝置情境下,確保同一留言在不同裝置上的通知狀態與內容一致。
- 使用者教育:引導用戶在裝置設定中允許背景活動與推播,減少人為設定對通知的影響。
實務要點
- 為核心通知設置高優先級,並在裝置端實作本地快取功能,讓在網路恢復後能快速顯示最近留言。
- 設計多通道策略,若某條通道受省電機制影響,另行透過另一條通道送达以維持穩定性。
- 建立裝置層級的監控,收集裝置型號、作業系統版本、網路類型與信號強度,找出高風險組合。
- 進行場景模擬測試,驗證 Doze、低電量模式與網路切換下的通知表現。
外部資源
- 針對 iOS 與 Android 的省電與推播策略差異,可參考與對比的討論與實務文章,協助你設計更穩健的裝置端方案。
圖像說明
- 裝置端策略示意圖,凸顯省電與背景執行對通知時效的影響。
Photo by Daniel Moises Magulado
混合推播與替代通知策略
單一推播通道往往無法覆蓋所有情境,於是需要混合推播與替代通知策略。當在關鍵時刻需要更高的可用性時,拉取機制或替代通知能提供額外保護層,降低單一路徑的風險。
- 混合推播的適用場景:高併發時,透過多條通道分散壅塞,確保至少有一條通道能在較短時間內到達裝置。
- 拉取機制的時機點:在裝置端設定「輪詢」或「拉取」的快速路徑,當推播延遲或中斷時,裝置主動拉取最新留言摘要。
- 實作要點:設計清晰的狀態同步機制,確保訊息在各通道間的一致性與正確性,避免重複推送或內容落差。
- 風險與監控:混合路徑增加了系統複雜度,因此需要更健全的日誌與指標,確保能快速定位問題。
實務要點
- 在核心通知上建立多通道冗餘,並設定明確的切換條件與通知版本控制。
- 為拉取機制設計快速路徑,避免用戶在網路恢復後必須等待整個輪詢週期完成才能看到新內容。
- 設置端到端的對齊時間戳記,確保多通道情境下的到達時間與內容一致性。
- 監控混合路徑的併發與失敗率,定期評估是否需要調整通道優先級。
外部資源
- 了解多通道推播與替代通知的實務案例,有助於你在不同產品階段採用合適策略。
- 參考 APNs 與 FCM 的實務比較與解析,可協助你理解不同機制的併發與延遲特性,進一步設計混合策略。
- 文章也討論了如何在跨平台環境中保持通知的一致性與可靠性。
圖像說明
- 混合推播與替代通知流程示意,幫助你直觀理解多通道協同的運作。
Photo by Daniel Moises Magulado
地區與裝置類型的考量
不同地區與裝置類型在推播通道上有差異,必須因地制宜調整策略。跨區域部署時,需考慮網路品質、通道可用性與裝置偏好差異,確保跨區覆蓋的一致性。
- 區域差異:某些地區的推播服務穩定性、網路可用性與設備普及度不同,需針對性選擇通道與設定優先級。
- 裝置類型差異:智慧型手機、平板、穿戴裝置等對推播與背景執行的支援度不同,需分別優化。
- 調整要點:在不同地區建立分區的監控與測試,定期校正閾值與 SLA,確保跨區域的一致性。
實務要點
- 建立地區化的推播策略模板,涵蓋網路條件、裝置分佈與通道偏好。
- 針對高普及裝置與新版本作業系統,做前瞻性優化與測試。
- 與地區運營團隊合作,持續收集使用者回饋,調整通知頻率與顯示策略。
外部資源
- 可參考跨區域推播實務與討論,作為調整策略的參考。
圖像說明
- 地區與裝置差異的視覺化示意,幫助你在企劃層面把握跨區域覆蓋的核心難點。

Photo by Gratis AI
外部連結參考
- APNs 與 FCM 的實務比較與解析,協助理解不同機制的傳遞機制與延遲特性。
- iOS 與 Android 的推播省電策略差異,幫你制定跨平台的穩健策略。
- Reddit 與 Apple 討論區的實際案例,提供現場情境的洞見。
若你需要,我也可以提供更多具體的測試清單與落地檢核點,讓你的推播優化計畫更具體、更易落地。
參考與延伸閱讀
- https://blog.csdn.net/paincupid/article/details/130475321
- https://www.infoq.cn/article/bicevkad24oqjqugy39g
- https://blog.csdn.net/sinat_28461591/article/details/148514339
結語
透過系統性的推播渠道優化與裝置端協同,你能顯著降低端到端延遲,提升使用者在手機上的通知體驗。接下來的章節將聚焦於實測與落地清單,幫你把前述策略轉化為可落地的實務步驟。
實作指南與最佳實務
在本節中,我們聚焦手機語音留言通知的實作要點,從架構與技術選型到整合與部署流程,再到監控與持續優化,給出具體可落地的做法。透過清晰的分工與可驗證的指標,團隊能快速推動優化,提升通知的時效與穩定性。為了協助你快速建立實務框架,以下內容貼近實務場景,並穿插實作清單與檢核點,讓你能直接照抄執行。
在本文中,推送相關的核心概念會以實務角度呈現,並搭配可參考的外部資源。你可以把 APNs、FCM 與自有機制視為三條主線,各自的優缺點與適用場景都在下面的說明中逐一揭示。若需要更深入的技術細節,也可參考相關技術文章與實務分享,例如 APNs 與 FCM 的實務比較與解析,以及 FCM 架構總覽與實作要點。
導引性說明
- 本節結構設計成可直接轉化為專案文件與開發任務清單。
- 針對不同裝置與網路情境,提供分階段落地方案與風險控管要點。
- 同時留意跨區域部署的差異,確保在不同地區的使用者都能獲得穩定的通知體驗。
架構與技術選型
選型決定了通知的路徑與維運成本,直接影響端到端延遲與穩定性。下面列出常用的推播框架、伺服器組合與 API 設計要點,以及各自的優缺點與適用場景,幫你快速做出決策。
- APNs(Apple Push Notification Service)作為 iOS 端的核心通道
- 優點:終端原生通道,延遲通常較低,裝置端呈現更及時。
- 缺點:與 Apple 審核、裝置註冊與憑證管理綁定較緊,跨平台整合需要額外層級。
- 適用場景:主要以 iOS 為主的推播,追求低延遲與高穩定性的單通道設計。
- 參考資源:APNs 的實務比較與解析可以提供進一步的架構洞見。
- FCM(Firebase Cloud Messaging)作為跨平台推播中介
- 優點:跨 Android、iOS 與 Web 的統一接口,集中管控、易於擴展。
- 缺點:在 iOS 上最終還要經由 APNs 轉送,路徑相對較長,需注意跨通道的一致性。
- 適用場景:多平台需求、需要統一分析與管理時效的情境。
- 參考資源:FCM 架構總覽、跨平台訊息處理流程等相關文檔。
- 自有推播機制(自家伺服與自建路徑)
- 優點:高度控管併發、排隊與 QoS,可以滿足特定 SLA 與自定義策略。
- 缺點:維運成本高,穩定性與可擴展性需自行持續投入監控與優化。
- 適用場景:對併發、可靠性、與內部系統深度整合有嚴格需求的企業級方案。
實務要點
- 優先以 APNs 為核心,若跨平台需求高且要統一邏輯,搭配 FCM 作為集中管理層。
- 自有機制適用於高併發與高價值通知,但需建立端到端日誌、時間戳與容錯機制,避免單一路徑成為瓶頸。
- 為每個通道設立 SLA 與監控指標,確保跨通道的通知時間可追蹤、可比對。
外部資源與參考
- APNs 與 FCM 的實務比較與解析,協助理解不同機制的傳遞機制與延遲特性。
- APNs 與 FCM 的實務比較與解析
- Firebase Cloud Messaging – 架構總覽,說明裝置註冊、訊息生命周期與生命週期流程。
- Firebase Cloud Messaging – FCM 架構總覽
圖像說明
- 推播路徑的全景示意,幫助你快速理解不同通道在端到端的影響。
整合與部署流程
自動化與風險控管,是把設計落地成可運作系統的關鍵。以下內容提供 CI/CD 流程、測試與回滾的實作要點,並強調自動化與風險控管的實務做法。
- CI/CD 基礎設計
- 版本控制與分支策略:針對推播相關的改動,設置 feature/ 推播優化分支,並建立自動化測試與部署。
- 自動化測試:單元測試、整合測試與端到端測試並行進行,確保推播行為在各通道上符合預期。
- 造訪權限與憑證管理:自動檢查 APNs、FCM 等憑證有效性,避免部署時憑證過期造成中斷。
- 測試與回滾
- 測試分階段進行:先在沙盒環境驗證,再推向預量與灰度,最後全量上線。
- 回滾機制:建立可快速回滾的機制與清單,包含版本號、時間戳與變更摘要,避免新變更引入風險。
- 監控與告警:併發量、到達率、平均延遲等指標建立自動告警,發現異常時能第一時間降級或回滾。
- 自動化部署要點
- 基礎架構即代碼化:使用 IaC 方案定義伺服與推播服務的部署、網路配置與安全性策略。
- 金鑰與憑證的安全管理:憑證更新、輪換與存取控制要自動化,降低人為錯誤。
- 日誌與追蹤:集中日誌與時間戳對齊,方便跨通道追蹤問題與性能瓶頸。
外部資源與案例
- 相關的技術討論與實作觀點可提供設計參考,在高併發場景下也能找到實用的重試與排隊策略。
- 使用 FM C 的實務分享與架構案例,能為你的跨平台方案提供參考。
圖像說明
- 伺服端與部署流程的示意圖,協助團隊理解整體部署關係。
監控、報告與持續優化
建立監控儀表板、定期檢視報告與迭代計畫,確保推播品質穩定。以下重點幫你建立端到端的可觀測性,以及以數據為基礎的改進節點。
- 指標與儀表板
- 端到端延遲與到達率:分別關注伺服端產生、推播轉發、網路傳輸與裝置呈現四個節點的延遲與成功率。
- 各通道的 SLA 達成狀況:比較 APNs、FCM 與自有機制在不同情境下的表現。
- 高風險裝置與地區分布:建立裝置型號、作業系統版本、網路類型與地區的風險分群。
- 成本與併發性:監控每條通知的成本與併發量,避免預算風險或資源瓶頸。
- 定期檢視與迭代
- 每週檢視核心指標與異常事件,制定對應的優化計畫。
- 每月根據使用者回饋與實測結果,調整推播策略與閾值。
- 以 A/B 測試驗證不同通道配置、重試策略與內容更新頻率對用戶行為的影響。
- 迭代落地
- 將測試結果轉化為明確的改動清單,分配到產品、後端與前端團隊。
- 建立跨部門的回報機制,確保風險與優化都能被快速處理。
外部資源與參考
- 推播機制的專業文章與案例,提供不同情境下的觀察與對比。
- Reddit 與 Apple 討論區的實際案例,補充多裝置與網路條件下的觀察。
圖像說明
- 監控與報告的儀表板設計示意,幫助你在實務工作中快速上手。
外部連結參考
- APNs 與 FCM 的實務比較與解析,協助理解不同機制的傳遞機制與延遲特性。
- iOS 與 Android 的推播省電策略差異,幫你制定跨平台的穩健策略。
- Reddit 與 Apple 討論區的實際案例,提供現場情境的洞見。
若你需要,我也可以提供更多具體的測試清單與落地檢核點,讓你的推播優化計畫更具體、更易落地。
參考與延伸閱讀
- APNs 與 FCM 的實務比較與解析,協助理解不同機制的傳遞機制與延遲特性。
- iOS 與 Android 的推播省電策略差異,幫你制定跨平台的穩健策略。
- Reddit 與 Apple 討論區的實際案例,提供現場情境的洞見。
結語 透過系統性的推播渠道優化與裝置端協同,你能顯著降低端到端延遲,提升使用者在手機上的通知體驗。接下來的章節將聚焦於實測與落地清單,幫你把前述策略轉化為可落地的實務步驟。
FAQ 常見問題解答 (FAQ 常见问题解答)
在本節中,我們以實務視角回應常見疑問,幫助你快速理解推送延遲的成因、檢測方法,以及不同區域與裝置條件下的差異。為了方便實務落地,我們會用清晰的步驟與實務要點來指引。文中亦自然引入相關的簡體詞,讓閱讀更貼近實際情境。以下內容適合在手機語音留言通知的整體優化專案中直接使用。
- 簡體關鍵詞變體示例:推送、推播、推送通知、推播、消息推送
FAQ1 簡體提問:推送延迟的主要原因是什么?
手機語音留言通知的延遲,往往是多個節點共同作用的結果。核心原因分成三大層級:伺服端、推播通道與裝置端。伺服端若產生事件較慢、或日誌時間戳不一致,就會讓整個路徑出現滯後。推播通道的併發、排隊與網路狀況,會把通知送達裝置的時間拉長。裝置端的省電模式、Doze 模式、背景執行限制與網路切換,也同樣會影響顯示時點。要降風險,需從端到端設計與測試開始,確認瓶頸位於哪一個節點。
- 端到端視角的觀察要點
- 伺服端事件產生與推送回應的時間戳是否一致
- 推播通道的併發壓力與重試機制是否過激
- 手機端的背景執行與省電設定是否阻塞通知呈現
- 實務要點
- 建立統一的時間戳基準,讓伺服端、推播伺服與裝置端的時間能對上
- 在高併發時段,採用多通道冗餘與優先級分流
- 對核心通知設定更嚴格的 SLA,並開啟端到端監控看板
參考閱讀與實務討論
- Reddit 使用者的延遲案例與多裝置情境分析,能提供直觀的場景對照:https://www.reddit.com/r/Tello/comments/16komqu/delayed_notification_of_voicemail_on_iphone_12/?tl=zh-hant
- Apple 討論區中關於通知延遲的討論,有助於從設定與網路因素理解問題:https://discussions.apple.com/thread/252150872?page=2
圖像說明
- 推播路徑全景示意,便於快速掌握各節點的可能延遲點。
Photo by Szabó Viktor
實例說明
- 案例 A:伺服端產生通知與裝置端顯示相差不大,但雲端併發高,導致裝置端出現 1–2 秒的延遲,對即時性要求不高的場景影響較小。
- 案例 B:網路不穩定時通知到達時間拉長,使用者可能錯過第一時間回覆,需透過多通道併發或拉取策略補救。
- 案例 C:同一留言透過多通道併發發送時,某些通道延遲較長,造成裝置間通知時間不一致。
結論要點
- 端到端延遲包含伺服端產生、推播中轉、網路傳輸與裝置呈現四個節點
- 伺服端快速產生不等於到達就等於即時呈現,通道與裝置策略同樣重要
- 以日誌與時間戳記追蹤,能快速定位瓶頸
FAQ2 簡體提問:如何快速检查推播是否延迟?
要快速檢查推播是否延遲,建議採用「端到端測試與分段觀察」的組合方法。先在伺服端觸發通知事件,記錄事件產生時間;再透過選定推播通道發送,記錄回應與中轉時間;最後在裝置端接收並顯示通知,記錄實際顯示時間。比對三端時間點,即可判定延遲落在哪個節點,進而採取對策。
快速檢測步驟
- 設定測試通知,確保事件產生時間可在日誌中追蹤
- 啟動推播通道,記錄伺服端回應與中轉時間
- 讓裝置端接收並顯示通知,記錄用戶看到通知的時間
- 對照預期時間,算出端到端延遲與到達率
- 如發現異常,重複測試,逐步定位瓶頸
檢測要點
- 使用一致的時間戳基準,避免不同系統時區造成誤差
- 對不同裝置與網路條件分別測試,找出高風險組合
- 建立自動化測試流程,定期執行,確保變更不會破壞時效性
實務做法與工具
- 將伺服端事件時間與裝置端顯示時間做關聯,建立跨通道的視圖
- 設置自動告警,當平均延遲或 P99 延遲超出門檻時通知負責人
- 使用日誌聚合工具,統一時間格式與欄位,方便追蹤
外部資源與案例
- 進階推播架構與測試策略的實務分享,幫助你設計自動化測試流程
- 圖解推播端到端流程的文章,提供視覺化檢測思路
圖像說明
- 實測流程框架示意,便於團隊落地。
Photo by Brett Jordan
實務要點
- 以測試矩陣覆蓋不同裝置、系統版本與網路條件
- 建立日誌與時間戳對齊的自動化流程
- 針對高價值通知設定嚴格的 SLA 與監控
FAQ3 簡體提問:不同地区的推送是否有差异?
不同區域在網路品質、裝置型號分佈、推播服務的可用性與穩定性上確實有差異。區域差異會影響多條通道的表現,像是在某些地區 APNs、FCM 或自有機制的併發與路徑穩定性不同。實務上,需要建立區域化的測試與監控,並依地區特性調整通道偏好與 SLA。
區域差異的實務要點
- 網路品質與覆蓋度:不同地區網路波動與信號穩定性不同,影響推播的到達時間
- 裝置分佈與作業系統版本:當地常用裝置與 OS 版本不同,需對應調整通知策略
- 通道可用性與成本:某些區域的某些通道可能穩定性較低,需設置替代路徑
- 監控與調整頻率:區域性數據需要定期校正閾值與 SLA
實務要點
- 建立區域模板,包括網路條件、裝置分佈與通道偏好
- 針對高普及裝置與新版本,提早進行前瞻測試與優化
- 與地區運營團隊密切合作,快速收集使用者反饋並微調策略
外部資源與案例
- 相關跨區域推播的實務討論能提供實務參考
- Reddit 與討論區的案例,補充不同地區的實際情況觀察
圖像說明
- 地區與裝置差異的視覺化示意,協助企劃時更好地掌握區域差異。
Photo by Gratis AI
整合與落地建議
- 為每個地區設定專屬的監控指標與 SLA,便於跨區域協同
- 針對高普及裝置與新版本,實施先行測試與差異分析
- 透過多地區的併發與網路條件模擬,驗證整體策略的穩健性
圖片與引文說明
- 圖像皆來自 Pexels,提供高品質的視覺補充,並附上授權照片作者。若需要,可再加入更多符合內容的示意圖,提升閱讀體驗。
參考與延伸閱讀
- APNs 與 FCM 的實務比較與解析,協助理解不同機制的傳遞機制與延遲特性
- iOS 與 Android 的推播省電策略差異,幫你制定跨平台的穩健策略
- Reddit 與 Apple 討論區的實際案例,提供現場情境的洞見
結語 透過上述 FAQ 的清晰解答與實務指引,你可以快速定位推播延遲的核心原因,並用可落地的策略提升手機語音留言通知的即時性與穩定性。若需要,我可以幫你把這些內容整理成可直接放進專案文件的檢核清單與測試腳本,讓團隊更高效地落地執行。
Conclusion
手機語音留言通知的延遲,源自伺服端、推播通道與裝置端三個節點的共同影響。掌握端到端的觀測與多通道冗餘策略,是降低延遲、提升回覆率的關鍵。透過清晰的指標、穩定的通道設計,以及裝置端的智慧策略,你可以讓通知在多地區與多裝置環境中穩定抵達。
結合實務步驟落地,先建立端到端日誌與時間戳統一基準,並在伺服端、推播與裝置端設計嚴格的 SLA。再以多通道冗餘與拉取機制做風險分散,於高併發與網路波動時仍能保證核心通知的即時性。完成這些後,整體通知體驗就能更一致、可信。
歡迎把你在實務中遇到的延遲情境與解決方案,留言分享。若想更快速落地,可下載我的實作清單與檢核表,按步驟完成設定,讓手機語音留言通知在各場景皆穩定。感謝你的閱讀,持續優化,讓用戶體驗成為你的最大競爭力。
